In this post, I would like to talk about Contrastive Learning and an inspirational paper I’ve read on Self-Supervised Contrastive Learning. Some of the ideas in the paper are quite interesting and worth sharing.
Self-Supervised Contrastive Learning
So before dive into self-supervised contrastive learning. Let’s first talk about the relationship between these two concepts.
Why Self-supervised?
In Machine Learning or Deep Learning, labels come at a price. So the idea of self-supervised learning is quite straightforward, to exploit the intrinsic information in the unlabeld data. To make use of unlabeled data, one way is to set/create the learning objectives properly so as to get supervision from the data itself.
And in Self-Supervised Learning, we want the machine to learn the representation of the data by performing pretext task. More information on Self-Supervised Learning and pretext tasks could be found here 1
What is Contrastive Learning?
Contrastive Learning is a learning paradigm that learns to tell the distinctiveness in the data; And more importantly learns the representation of the data by the distinctiveness.
A ellaborated explanation of Contrastive Learning as well as self-supervised Contrastive Learning (with the example of SimCLR) could be found at2 (which is also explained in the slide)
Contrastive Puzzle Example
Therefore, the take away is that Contrastive Learning in the Self-Supervised Contrastive Learning merely serves as pretext tasks to assist in the representation learning process.
Concepts
Before delving into the similarity & loss functions in contrastive learning, we first denote three important terms for the type of data:
Anchor: we note as $x_+$
Positive: we note as $y_+$
Negative: we note as $y_-$
The aim of our contrastive learning is to pull the similar (positive) data toward the anchor data and pushes dissimilar (negative) data away from the anchor data.
Anchor, Positive and Negative
Similarity function
Cosine Similarity function
A frequently used similarity function is
$$\operatorname{sim}(u, v)=\frac{u^{T} v}{|u||v|} = cos(\theta)$$
It’s not hard to find that $\operatorname{sim}(u, v)$ is also the cosine value of $\theta$ which is the angle between $u, v$ thus the name cosine similarity. And in practice, we add an extra coefficient $\tau$ (temperature coefficient) to accelerate convergence (physical explanation could be found in this paper3)
NCE loss
$$\log \sigma\left(\operatorname{dis}\left(x_{+}, y_{+}\right) / \tau\right)+\log \sigma\left(-\operatorname{dis}\left(x_{+}, y_{-}^{i}\right) / \tau\right)$$
k-pair loss (Inspired by softmax)
$$-\log \frac{\exp \left(\operatorname{sim}\left(x_{+}, y_{+}\right) / \tau\right)}{\exp \left(\operatorname{sim}\left(x_{+}, y_{+}\right) / \tau\right)+\sum_{i=1}^{k} \exp \left(\operatorname{sim}\left(x_{+}, y_{-}^{i}\right) / \tau\right)}$$
k-pair loss is commonly used at the moment (2020), CMC also adopts this loss.
Contrastive Multiview Coding
Basic Info
This work was proposed by Yonglong Tian et al. It was built upon the idea of self-supervised contrastive learning frameworks, while CMC adopts multiple views as data (pairs) for contrastive learning pretext.
CMC with two views
Contrastive Loss
The contrastive loss between two views $V_1$ (anchor view), $V_2$ is calculated as
Here we refer to the concept of Mutual Information, Entropy, Conditional Entropy in Information Theory. A good Information Theory illustration could be found here 4.
An Intuitive Example
Imagine you met a dog wearing a mask like this.
A cute dog with a mask
You could tell that this is a dog, not a mask, because you not only saw the scene, but also heard its barking, and if you were lucky, you could even tell it’s a dog by feeling its fur.
So in the example, we use the mutual information in our three senses:
visual
acoustic
touching
to tell that it’s a dog, so can we exploit the same fashion in the perception of machine as well?
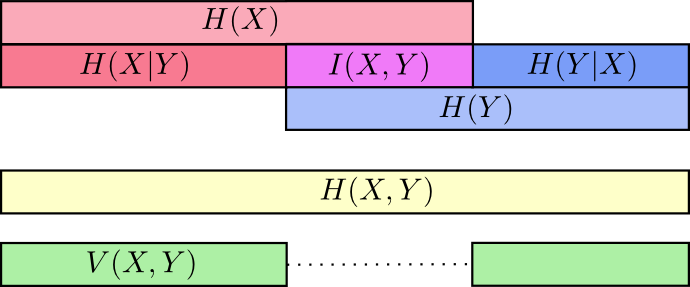
Mutual Information
Mutual Information Visual Explanation (from Christopher Olah’s Blog)
Mutual Information is calculated as
$$I(X;Y) = H(X)-H(X|Y)$$
and applying the formula for entropy and conditional entropy
$$\mathrm{I}(X ; Y)=\int_{\mathcal{Y}} \int_{\mathcal{X}} p_{(X, Y)}(x, y) \log \left(\frac{p_{(X, Y)}(x, y)}{p_{X}(x) p_{Y}(y)}\right) d x d y$$
With all these knowledge in mind, the author of CMC contends that the relationship between $\mathcal{L}_{contrast}$ and MI of the representations is
There’s an extra MI term for two views which serves as an upper bound since there are information loss during encoding, i.e. the process $z = f_\theta(v)$.
Therefore, the takeaway message from this part is as follows:
More Mutual Information will be “squeezed out” from two view data $v_1, v_2$ by increasing the number of negatives ($k$) or eliminating the contrastive loss.
In the view of Representation Learning
The aim of CMC is to learn a decent representation of the objects by contrasting multiple views of the objects to the views of other objects. The essence of CMC improving the representation of the objects is that by using CMC, the important information of the object (the mutual information between views for the same object) is embedded in the representation.
So naturally, a question arises, “How many mutual information do we need?” The author explained in a different paper5, and the main idea is that, there’s a sweet spot for how many bits of information a specific down-stream task $y$ needs, noted as $I(x;y)$
Sweet spot for the amount of mutual information
By training Self-Supervised Contrastive Learning, Mutual Information between views $v_1, v_2$ $I(v_1;v_2)$ is squeezed out, however, once the amount of mutual information (exploited to learn the representation) exceeds the sweet spot for downstream task $y$, the performance will begin to decline.
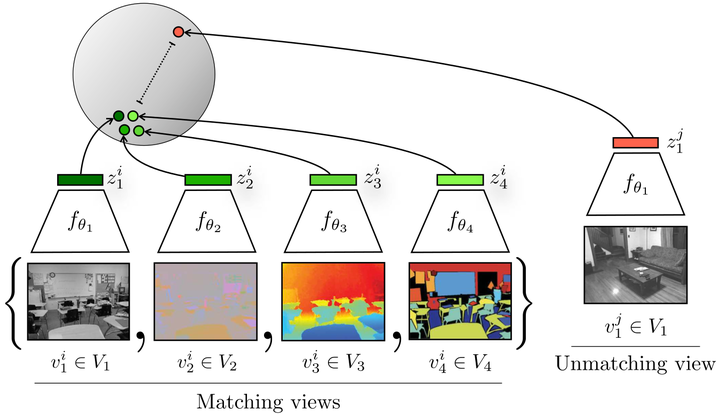 Credit: Yonglong Tian et al. Contrastive Multiview Coding
Credit: Yonglong Tian et al. Contrastive Multiview Coding