InkSight: Offline-to-Online Handwriting Conversion by Teaching Vision-Language Models to Read and Write

Feedback and correspondence
For questions, feedback, or issues with this post and open-source code, please contact Chengkun at: chengkun.li@epfl.ch. For questions regarding the paper, please contact corresponding author Andrii at: amaksai@google.com.
Overview
For centuries, handwritten notes have been a powerful tool for personal expression and information storage. In today’s digital world, handwritten notes offer a nostalgic charm but lack the convenience of digital formats—durability, easy indexing, and seamless integration with other digital content.
Now, with InkSight, a system built upon vision-language models, we’re taking a significant step toward converting offline handwriting to digital ink formats (online handwriting).

What is InkSight?
InkSight is designed to “derender” handwriting from an image into a sequence of digital ink strokes. This conversion allows a digital pen-and-paper experience from a simple photo of handwritten text, avoiding the need for specialized hardware like smart pens or digital paper.

This solution combines intuitions from how people read and write, even though obtaining large datasets of handwritten text with exact stroke information is challenging. Let’s first dive into the results of InkSight, and then explore how it works.
✍️ Word-level Samples

帮助 (help)

InkSight

洛桑 (lausanne)

CHRISTIANS

October

WELCOME

我爱你 (I love you)

though

PRIMING

The

regards

thoughts

experiment

math

福

你
📝 Full-page Samples





How Does InkSight Work?
InkSight’s model operates on both reading and writing “priors”—knowledge or tendencies humans apply to interpret and recreate text. These priors allow it to generalize across diverse handwriting styles and appearances, which are challenging to standardize in training data.
- Reading Prior: The model learns to identify textual elements within varied and complex images, and can be aided by general text recognition capabilities, including OCR.
- Writing Prior: This ensures that the output digital ink aligns with natural handwriting dynamics, capturing the order of strokes in an authentic, human-like way.
By integrating these priors, InkSight can produce robust digital inks that maintain both the semantic (content) and geometric (structure) properties of the handwritten input, making it uniquely adaptable to a wide range of visual conditions, from lighting variations to complex backgrounds.

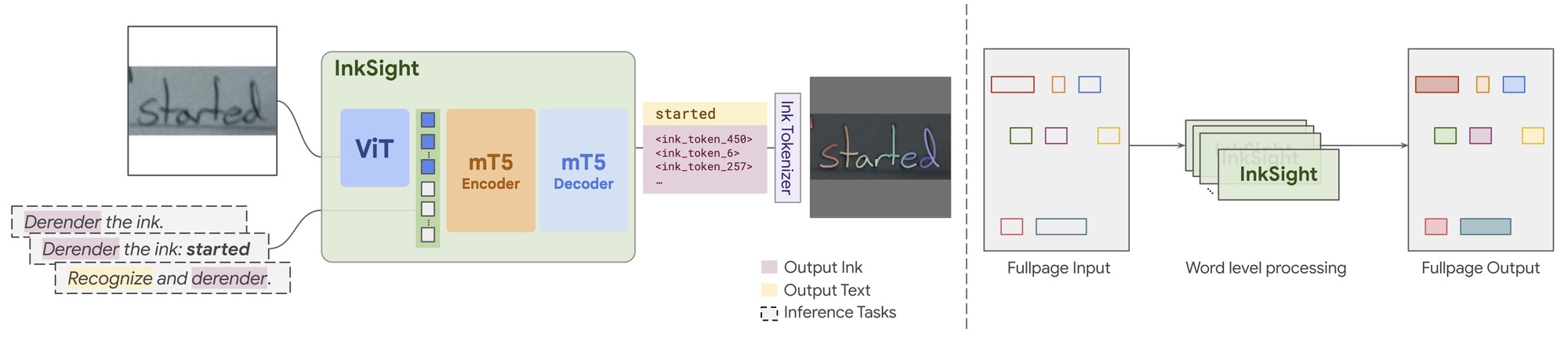
The InkSight model architecture is based on combining a Vision Transformer (ViT) encoder with an mT5 encoder-decoder Transformer, resembling the structure of Pathways Language and Image Model (PaLI):
![[gif]](inksight_animation_gif.gif){kind=link}
The model is trained using a unique multi-task training setup that includes five task types, each allowing the model to handle handwriting inputs of various complexities. Two derendering tasks (ink output), two recognition tasks (text output), and one mixed task
(text-and-ink output). Each type of task utilizes a task-specific input text, enabling the model to distinguish
between tasks during both training and inference.

A crucial and distinctive step for this modality is the ink tokenizer. It tokenizes the 2D space and encodes the sequential nature of digital ink in a format optimized for compatibility with large language models (LLMs) or vision-language models (VLMs).
To this end, we propose a novel ink tokenizer, that converts ink strokes into a sequence of discrete tokens, thus acting as the tokenizer for digital ink.
Digital Ink Tokenization
Digital ink is usually represented as a sequence of strokes $I = \{s_1, s_2, \cdots, s_n\}$, where each stroke $s_i$ consists of a sequence of $m_i$ (length of the $i$-th stroke) coordinate-time triplets, represented as $s_i = \{(x_i, y_i, t_i)\}_{i=1}^{m_i}$. Each digital ink stroke is normalized by resampling it at a fixed rate, reducing the sequence length with the Ramer-Douglas-Peucker algorithm, and centering it on a fixed-size canvas.
Ink tokenization starts with a “beginning of stroke” token, followed by tokens encoding the $x$ and $y$ locations of each sampled point. The token dictionary size, which balances rounding error with vocabulary size, is determined by a parameter $N$.
![[gif]](ink_tokenizer.gif){kind=link}
One of the major achievement with InkSight is its ability to move from word-level derendering to full-page derendering. This allows the model to handle entire pages of handwritten notes, identifying and derendering each word individually before seamlessly combining them into a cohesive digital ink document.
![[gif]](full_page_animation.gif){kind=link}
In the project, we use with Google Cloud Vision Handwriting Text Detection API for word-level bounding box detection. However, there are open-source and free alternatives like Tesseract OCR, docTR, etc. We provide code examples of using both free alternatives for full-page derendering in our GitHub repository.
Highlighted Findings
Human Evaluation Reveals High-Quality Digital Ink Generation
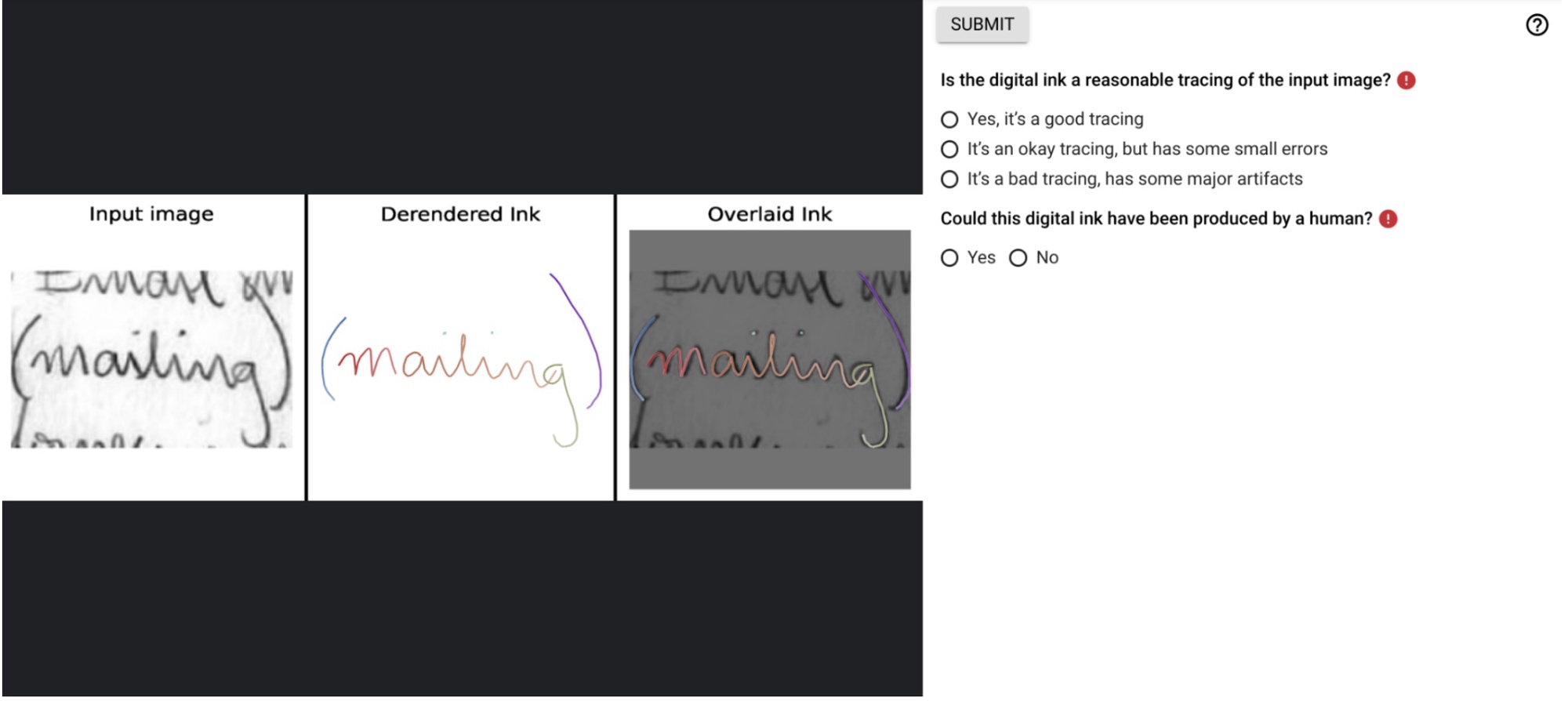
Our evaluation combined human assessment with automated metrics to validate InkSight’s performance. In a blind study, evaluators compared model outputs against human-traced samples without knowing their source. The results were exciting: 87% of InkSight’s outputs were judged as valid tracings of the input text, and remarkably, 67% were deemed indistinguishable from human-generated digital ink.
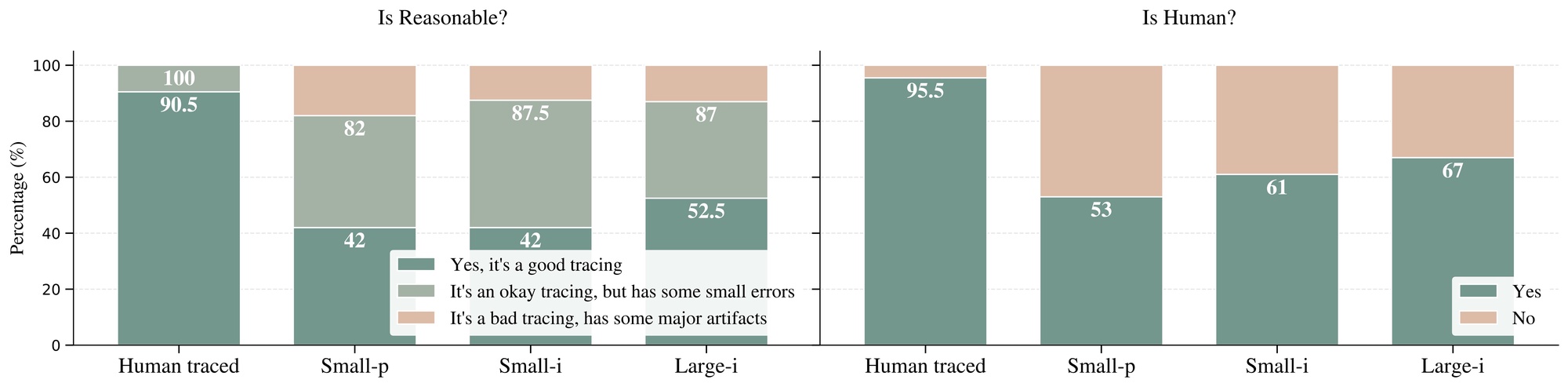
These human evaluations were conducted with 16 digital ink experts, each sample being assessed by three independent raters to ensure reliability (inter-rater reliability κ: 0.44-0.46).
The Role of Recognition Tasks (Reading) in Writing Quality
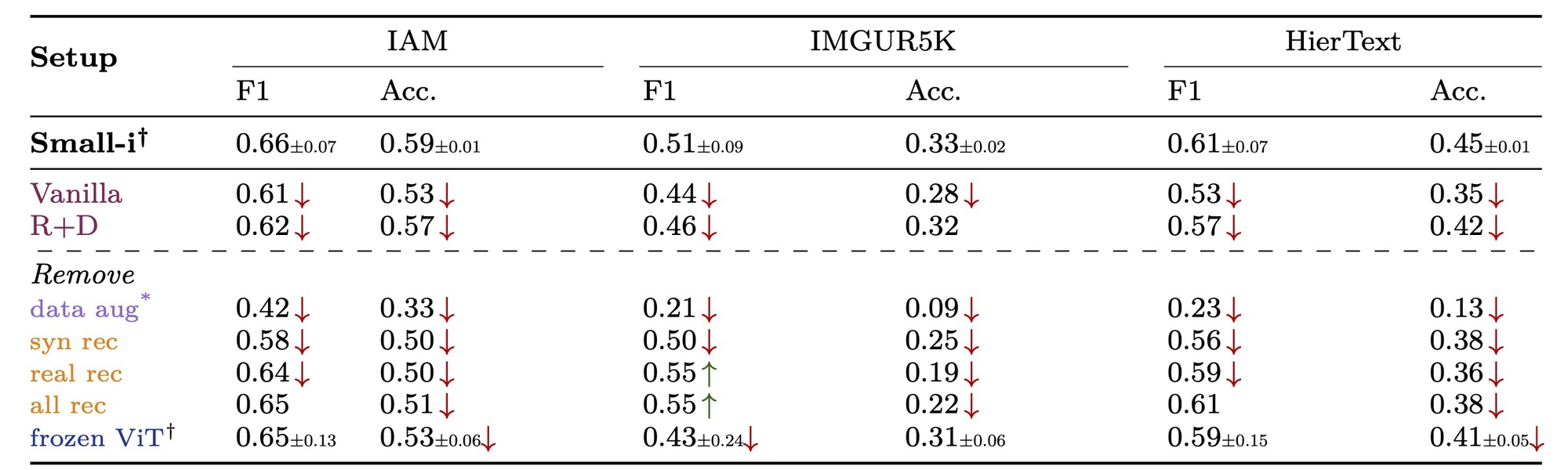
An interesting finding from our ablation studies emerges in the relationship between recognition and writing quality. When recognition tasks were removed from training (rows highlighted in yellow), the model maintained reasonable geometric similarity to input images (F1 scores) but showed marked decline in semantic consistency. On the HierText dataset, removing recognition tasks reduced accuracy from 0.45 to 0.13-0.38, while F1 scores remained relatively stable. This suggests that recognition training, or “reading,” plays a key role in producing semantically consistent writing, beyond simple visual pattern matching.
Handling Ambiguous Cases: The Impact of Inference Mode
Analysis of challenging cases reveals the critical role of inference strategy in handling ambiguous handwriting. Using “DESiGNÉRS” as an example: while Vanilla Derender captures basic geometry, it struggles with character precision (rendering ‘E’ and ‘ÉR’ as rough strokes). In contrast, Derender with Text maintains precise character structure by leveraging OCR input, while Recognize and Derender produces plausible tracings aligned with its own text recognition (using lowercase ’e’ and ’er’). This demonstrates how different levels of textual understanding yield distinct yet valid interpretations of ambiguous handwriting.


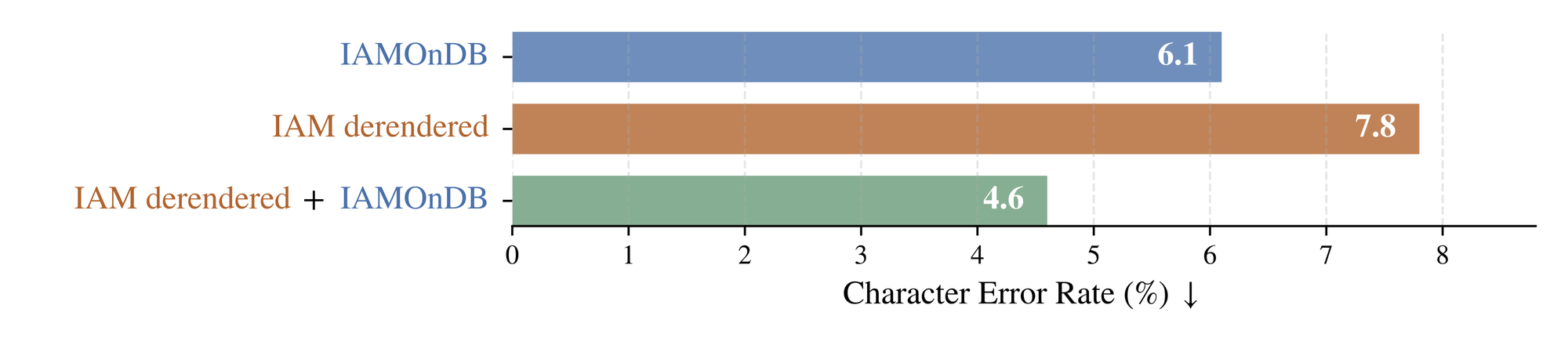
A Novel Data Source for Handwriting Recognition
Our experiments with handwriting recognition yielded informative results. Training with IAM derendered ink produced a Character Error Rate of 7.8%, performing worse than the 6.1% baseline established using IAMOnDB. However, when combining both IAMOnDB and IAM derendered data, the CER improved to 4.6%. This suggests that derendered ink, while not matching real data quality for training recognizer models in isolation, can serve as valuable complementary data for training recognition systems, opening new possibilities for improving handwriting recognition systems where high-quality digital ink data is scarce.
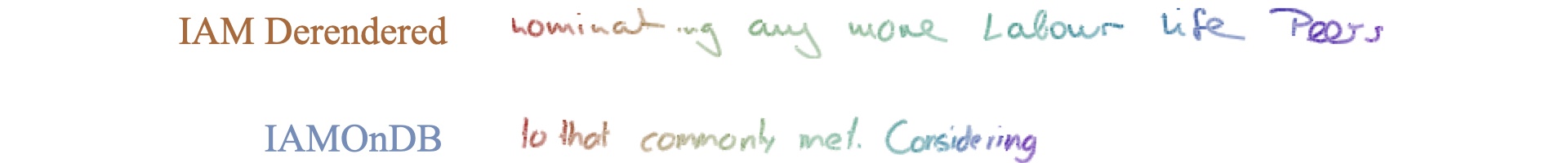
Limitations and Future Directions
While InkSight demonstrates strong capabilities in converting offline handwriting to digital ink, it encounters challenges in certain scenarios. The model can struggle with thick or variable stroke widths and highly ambiguous or distorted text. In full-page derendering, InkSight relies on accurate segmentation to avoid misalignment issues, especially on intricate page layouts. Additionally, minor details like punctuation can sometimes be omitted or duplicated, affecting the fidelity of the digital ink. These limitations highlight areas for future refinement, aiming to boost InkSight’s precision and adaptability across diverse handwriting styles and conditions.
Conclusion
InkSight introduces a novel approach to converting handwritten text from offline into online digital ink format. The system achieves this without requiring paired training data, making it readily applicable in real-world scenarios. Our evaluation demonstrates the model’s ability to handle diverse inputs - from basic handwriting to simple sketches - while maintaining semantic consistency and natural stroke dynamics.
Key aspects that set this work apart include its use of standard architecture components, well-designed training methodology, and ability to process full pages of handwritten notes. We make the Small-p model weights, inference code, and a curated dataset of synthetic and human-traced digital ink publicly available to support further research in this area.
While current limitations include constraints on input length and sketch complexity, the framework establishes a foundation for bridging the gap between physical and digital note-taking, opening new possibilities for handwriting digitization and recognition systems.
Data Mixture, Model Card, and Training
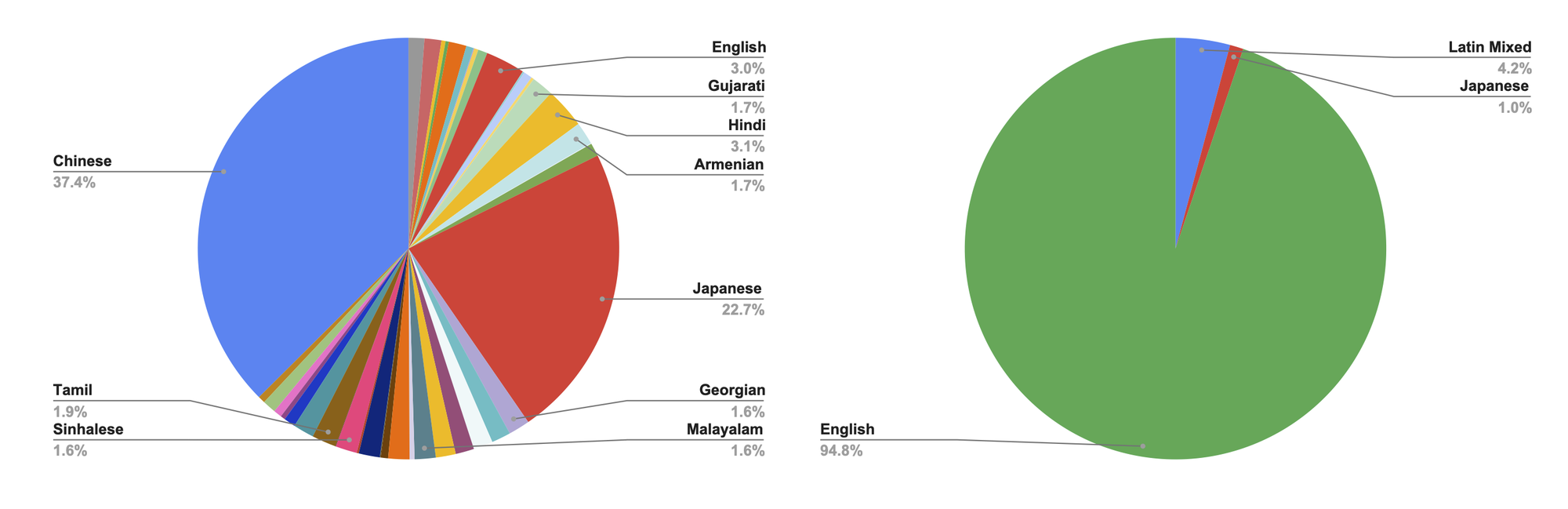
In-house Training Mixture
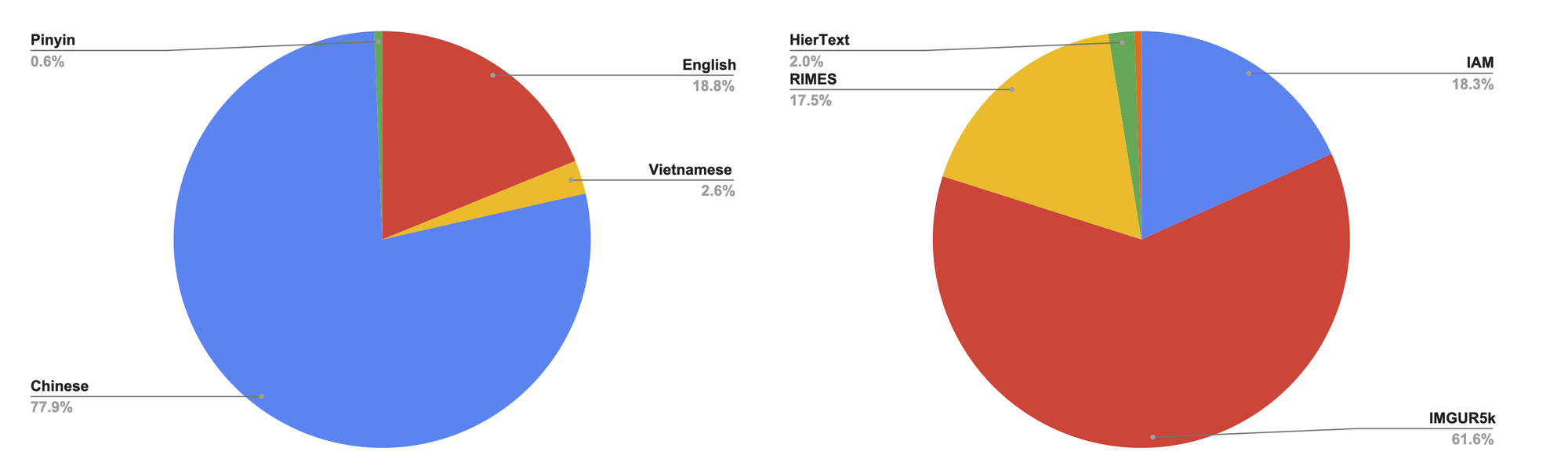
Small-p Training Mixture
| Task Type | Dataset | Number of Samples |
|---|---|---|
| Derendering | DeepWriting (words) | 89,565 |
| DeepWriting (lines) | 33,933 | |
| DeepWriting (characters) | 359,643 | |
| VNonDB | 66,991 | |
| SCUT-COUCH Chinese characters | 1,998,784 | |
| SCUT-COUCH Chinese pinyin | 156,535 | |
| OCR | IAM word-level (train) | 53,839 |
| IMGUR5k (train) | 181,792 | |
| RIMES word-level (train) | 51,738 | |
| HierText (train) | 5,978 | |
| ICDAR-2015 (train) | 1,535 |
Model and Training Summary
| Model Architecture | A multimodal sequence-to-sequence Transformer model with the mT5 encoder-decoder architecture. It takes text tokens and ViT dense image embeddings as inputs to an encoder and autoregressively predicts discrete text and ink tokens with a decoder. |
|---|---|
| Input(s) | A pair of image and text. |
| Output(s) | Generated digital ink and text. |
| Usage |
Application: The model is for research prototype, and the public version is released and available for the public. Known Caveats: None. |
| System Type |
System Description: This is a standalone model. Upstream Dependencies: None. Downstream Dependencies: None. |
| Implementation Frameworks |
Hardware & Software: Hardware: TPU v5e. Software: T5X , JAX/Flax, Flaxformer. Compute Requirements: We train all of our models for 340k steps with batch size 512. With frozen ViT encoders, the training of Small-i takes ∼33h on 64 TPU v5e chips and the training of Large-i takes ∼105h on 64 TPU v5e chips. |
| Data Overview | Training Datasets: The ViT encoder of Small-p is pretrained on ImageNet-21k, mT5 encoder and decoder are initialized from scratch. The entire model is trained on the mixture of publicly available datasets described in the previous section. |
| Evaluation Results | Evaluation Methods: Human evaluation (reported in Section 4.5.1 of the paper) and automated evaluations (reported in Section 4.5.2 of the paper). |
| Model Usage & Limitations |
Sensitive Use: The model is capable of converting images to digital inks. This model should not be used for any of the privacy-intruding use cases, e.g., forging handwritings. Known Limitations: Reported in Appendix I of the paper. Ethical Considerations & Potential Societal Consequences: Reported in Sections 6.1 and 6.2 of the paper. |
Acknowledgements
The authors thank Leandro Kieliger, Philippe Schlattner, Anastasiia Fadeeva, Mircea Trăichioiu, Efi Kokiopoulou, Diego Antognini, Henry Rowley, Reeve Ingle, Manuel Drazyk, Sebastian Goodman, Jialin Wu, Xiao Wang, Tom Duerig, and Tomáš Ižo for their help and support.