RNN Attention and Transformer
Some notes on Attention and Transformer
 “Transformer” credit:
Unsplash
“Transformer” credit:
Unsplash
Why Attention? RNNs vs RNN + Attention
Before we talk about Transformers, let’s list some limitations of RNNs
- The hidden states failed to model long range dependencies
- Suffers from gradient vanishing and explosion
- Requires large numbers of training steps
- Its recurrence prevents parallel computation

Comparing with RNNs, Transformer networks have the attributes of
- It can facilitate long range dependencies
- There’s no gradient vanishing and explosion: (since #layers decreases)
- Attention could help to go back and look at particular input to decide the outputs
- Every step of generating the outputs is a training sample
Example of RNN + Attention
In this Seq2Seq with Attention example1, the attention mechanism enables the decoder to focus on the word “étudiant” (“student” in french) before it generates the English translation. This ability to amplify the signal from the relevant part of the input sequence makes attention models produce better results than models without attention.
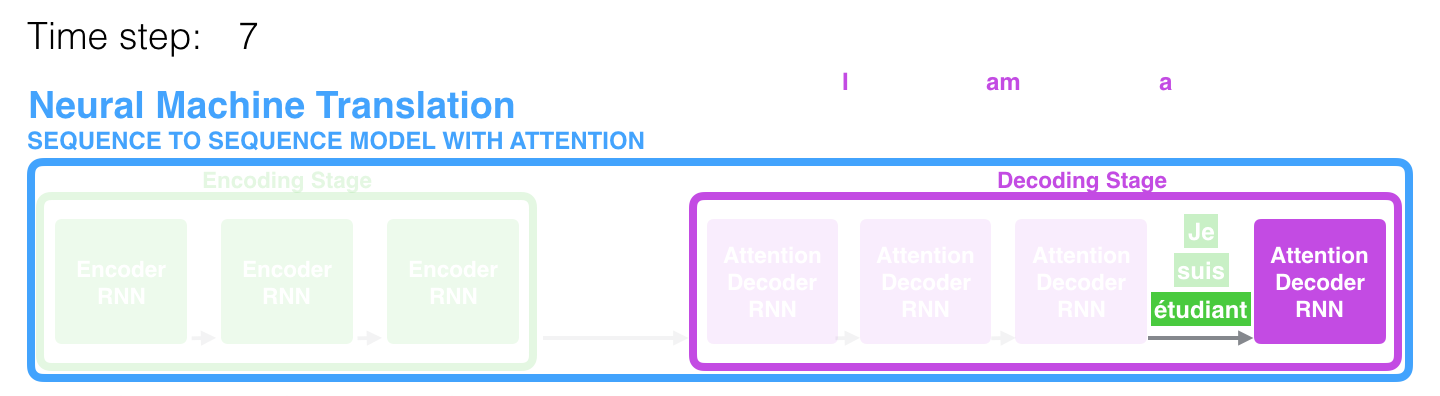

- The attention decoder RNN takes in the embedding of the
<END> token, and aninitial decoder hidden state. - The RNN processes its inputs, producing an output and a
new hidden state vector (h 4 ). The output is discarded. - Attention Step: We use the
encoder hidden states and theh 4 vector to calculate a context vector (C 4 ) for this time step. - We concatenate
h 4 andC 4 into one vector. - We pass this vector through a
feedforward neural network (one trained jointly with the model). - The
output of the feedforward neural networks indicates the output word of this time step. - Repeat for the next time steps

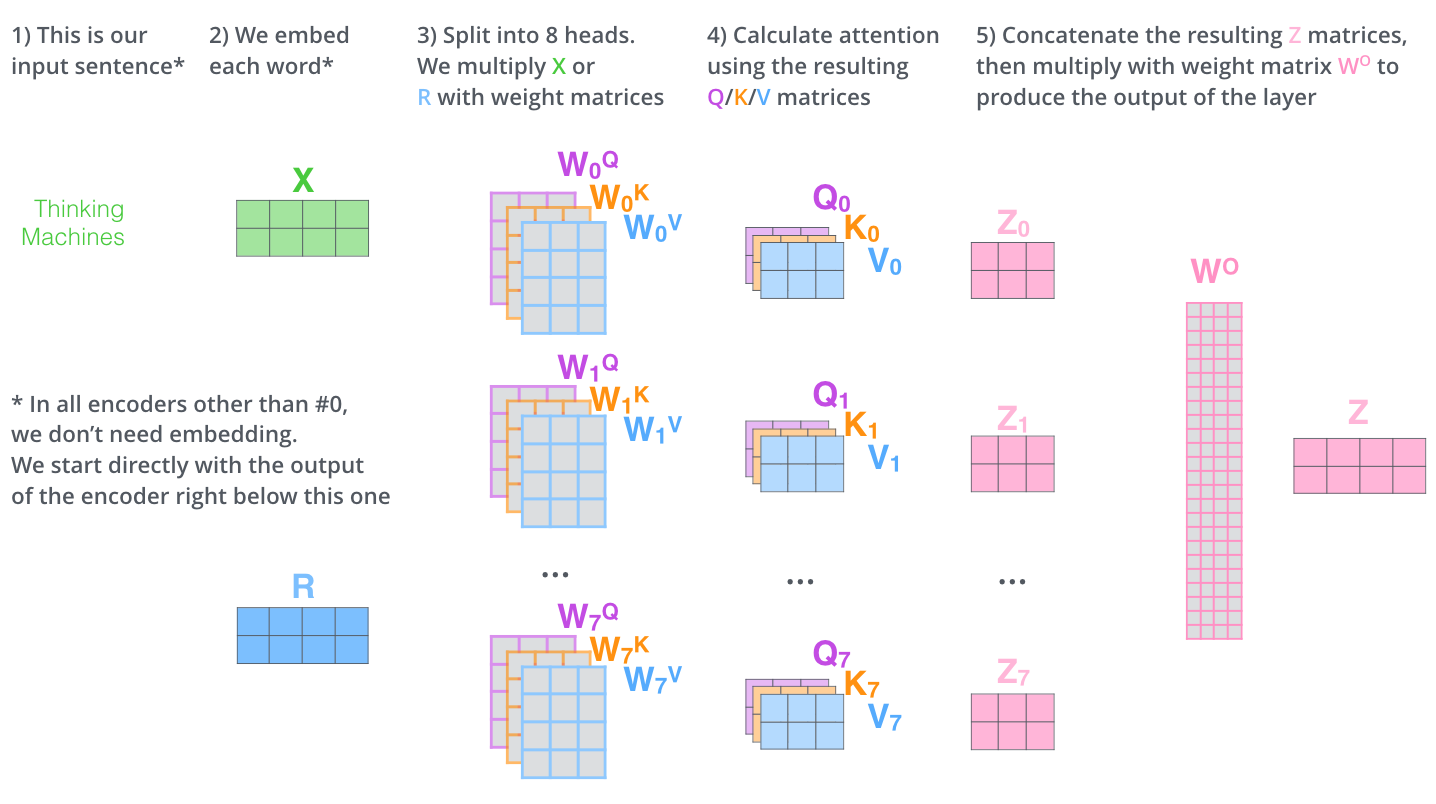
Whole process of Attention scoring
Multi-Head Attention Module
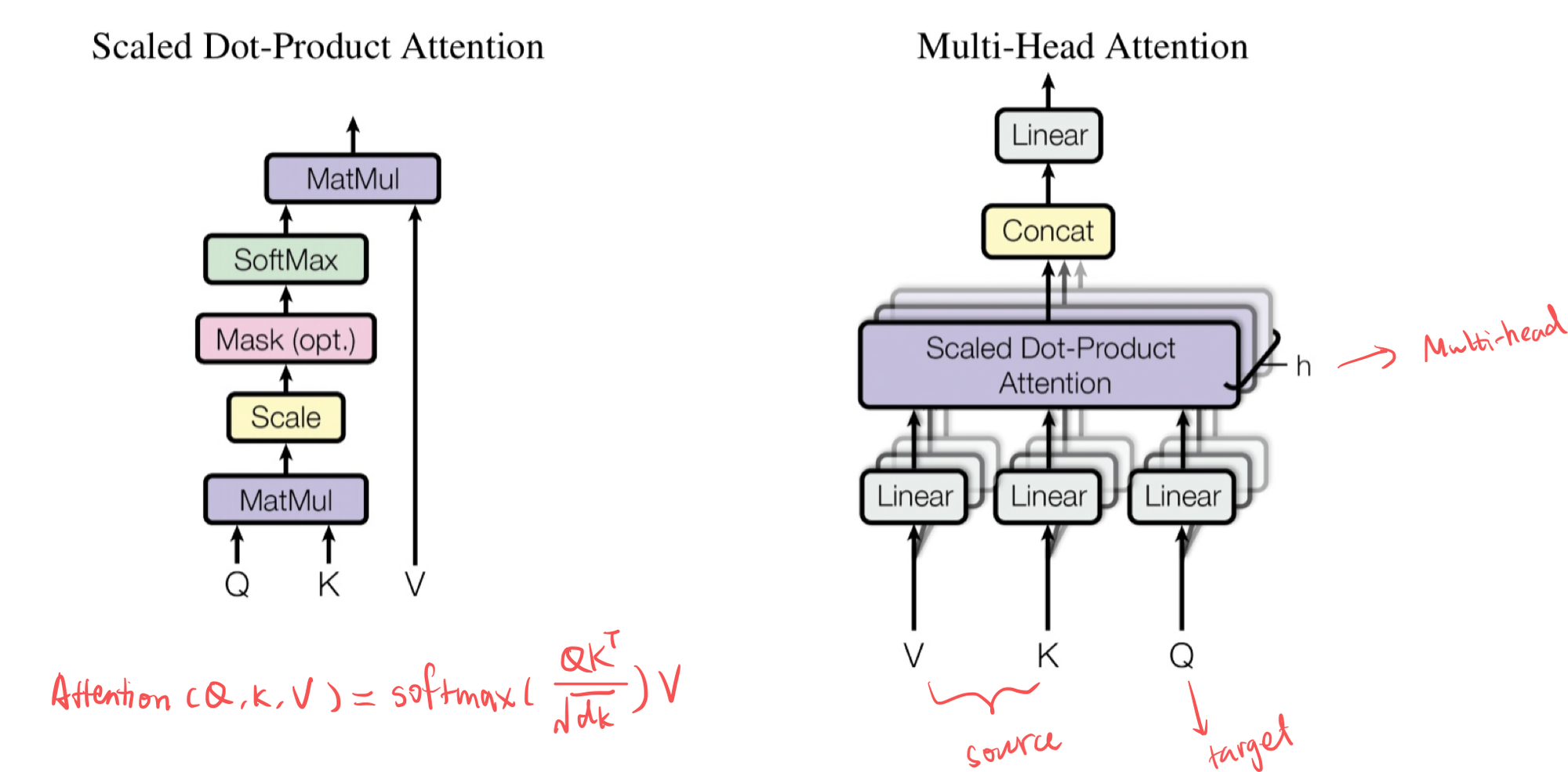
Three types of input vectors to the module:
- Value
- Key
- Query
The Attention is calculated as $$ \text{Attention}(Q,K,V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V $$
The illustration in this part is referred to the post2 please check out the original post for more details.
-
From post Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) ↩︎
-
Post The Illustrated Transformer by Jay Alammar ↩︎