 DC 轴承检测竞赛 无法识别小组
DC 轴承检测竞赛 无法识别小组
关于代码开源
题目与平台调研分析
- 题目背景: 轴承状态的监测和分析非常重要,它可以发现轴承的早期弱故障,防止故障造成损失。在所有类型的轴承故障诊断方法中,振动信号分析是最主要和有用的工具之一。
- 任务: 10分类问题,时序数据
-
参赛选手需要设计模型根据轴承运行中的振动信号对轴承的工作状态进行分类。
-
同一列的数据不一定是同一个时间点的采样数据。
-
训练集有792条记录,每个记录有6002列,第一列为轴承id,最后一列为故障类别(label),中间的6000列为振动信号时序数据。
-
评分算法: binary-classification 采用各个品类$F_1$指标的算术平均值,它是Precision 和 Recall 的调和平均数。 其中,$P_i$是表示第$i$个种类对应的Precision, $R_i$是表示第$i$个种类对应Recall。 $$ F_1=\frac{1}{n} \sum_{i}^{n} F 1_{i}=\frac{1}{n} \sum_{i}^{n} \frac{2 \cdot P_{i} \cdot R_{i}}{P_{i}+R_{i}} $$
如果一个分类器的性能比较好,那么它应该有如下的表现:Recall值增长的同时保持Precision的值在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高
轴承检测问题背景调研
故障数据数据产生原理

- 轴承故障可能发生在轴承的不同位置,包括内环,外环等等。
- 因为轴承故障,在轴承的表面以及损坏部位会产生不同的冲击。
- 这种冲击是不同于正常轴承产生的信号,其持续时间更长,光谱范围更宽。
振动检测方法

常用检测技术: 主要分为检测超声测量与振动特征信号
震动波形的一般特点
- 轴承部件的自振频率为500~2000HZ,轴承零部件受到冲击时,以它们的自振频率“瞬时扰动”。
- 大的冲击产生大的自振频率尖峰响应。
- 磨损严重时,共振附近会出现更多频率分量
- 损坏轴承振动信号呈现出周期性
文献调研123
-
一般预处理步骤
-
降噪(EEMD )
-
信号分解
-
-
特征选取方法:
- Energy entropy(熵)
- 奇异值
- 手工设计特征 —— 结合非线性特征与非平稳特征
-
一般使用模型:
- SVM
- 多层 BP 神经网络 (MLP)
- Bagging
算法设计
由于提供的数据是时序数据且时间不对齐,所以我们需要对数据进行特征提取。特征提取有两种方法,一种是通过模型自行学习提取数据,另一种就是传统的手工设计,通过对数据分析,手工设计特征,并利用一些分类器模型,通过前期学习,我们发现多分类SVM,随机森林与多层感知机可以进行应用
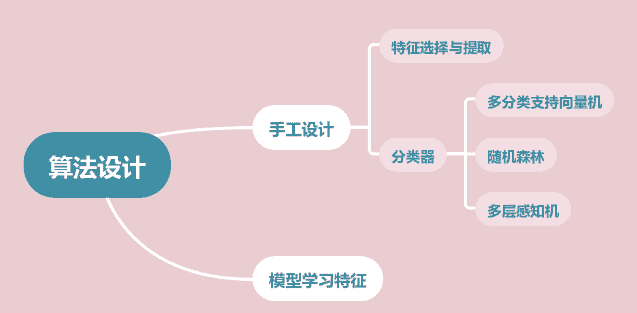
可分为两种流程:
-
手工设计特征,将设计好的特征输入到分类器中
优势:逻辑清晰,有大量先验知识可以借鉴
劣势:只能依靠经验和尝试去提取表现较好的特征
-
设计模型让模型自己学习数据中的特征
优势:模型可以自己学习数据中的特征,不再依赖先验知识
劣势:数据量小,需要进行数据增强的操作,同时训练时间较长
光看数据可能看不出什么名堂,因此我们制作了数据可视化讲数据转换为直观的动图
数据可视化
为了对数据进行分析,我们对数据进行了可视化的操作。对同一类的所有样本,对其时域振动,以及采样的时许信号,频域信号,采样后的频域信号进行了动画可视化。
以下可视化包含了信号的时域/频域可视化及采样后的时域信号对应的频域信号,频域信号为时域信号进行单边FFT操作
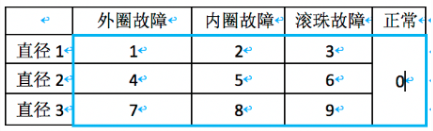
Label 0 正常

label 1 直径1外圈故障

label 2 直径1内圈故障

label 3 直径1滚珠故障

label 4 直径2外圈故障

label 5 直径2内圈故障

label 6 直径2滚珠故障

label 7 直径3外圈故障

label 8 直径3内圈故障

label 9 直径3滚珠故障

数据分析
从可视化中我们可以出,相同类样本振动相似,不同类振动存在区别。相同类样本的时域与频域信号有一定的相似性,不同类样本之间,时频域信号形状各不相同。
在时域信号上,可以充分的发现有振幅与周期不同,频域信号则是频率分布的不同。
- 损坏不同,震动方式不同,拥有不同的特征频率
- 损坏导致震动频谱增加,持续时间缩短
- 可以在时域里与频域里分析特征提取
- 峰值与峰度不同
特征设计
针对需要手工设计的模型,我们
模型使用
我们准备采用以下的模型
基于手工设计特征的分类器
多分SVM
支持向量机( SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,SVM可以通过核函数方法进行非线性分类,利用软间隔解决样本噪声误差的问题。
根据数据特点,核函数选择:径向基核函数。
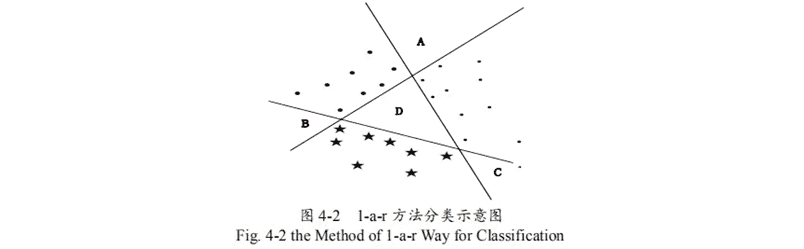
解决多分类问题:利用标准SVM的计算流程有序地构建多个决策边界以实现样本的多分类,通常的实现为“一对多”和“一对一” 。
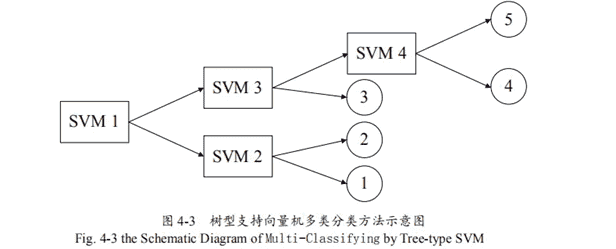
训练集数据共 M个类,one-against-one方法是在每两个类之间都构造一个binary SVM,从根节点开始,采用某种方法将该节点所包含的类别划分为两个子类,然后再对两个子类进一步划分,如此循环,直到子类中只包含一个类别为止。这样,就得到了一个倒立的二叉树。
多层感知机
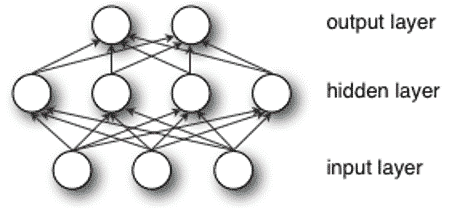
实际上就是一个拟合非线性函数的过程,不多解释了 $$ f(x)=G\left(b^{(2)}+W^{(2)}\left(s\left(b^{(1)}+W^{(1)} x\right)\right)\right) $$

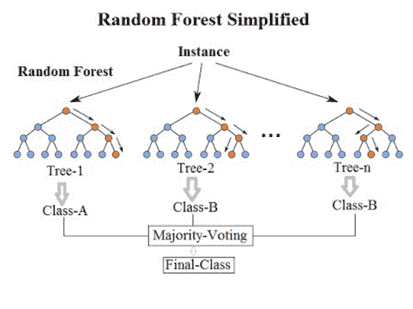
随机森林
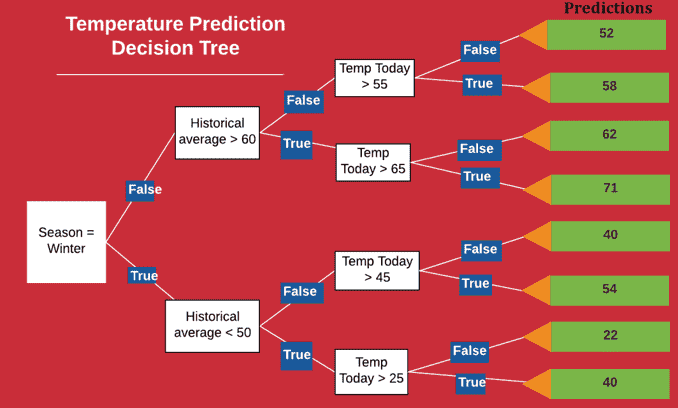
这个比较有意思,可以细讲一下,随机森林离不开决策树,决策树可以理解成一个 if-else 判断结构的模型:
随机森林中是由决策树组成的,它的每一个决策树都只针对原数据集中的一个子数据集因此模型受到原数据集中的数据分布的影响较小

随机森林对于新的数据的加入以及数据的缺失表现的很鲁棒,看下图在数据增加的情况下分类决策边界基本没怎么变

数据集具有类别及数值特征的时候可以考虑用随机森林
基于模型自己学习特征的分类器
我们发现音频信号和震动信号十分相似,因此希望从音频分类(Audio Classification)的模型中获取灵感

- 基于一维卷积的网络
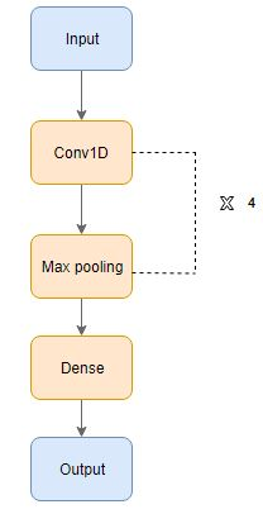
一维卷积层可以很好地应用于传感器数据的时间序列分析同样也可以很好地用于分析具有固定长度周期的信号数据比如音频信号
已有工作及结果 ( 持续更新中 )
| Model | Accuracy | Train / Test Split | 小结 |
|---|---|---|---|
| Random Forest 混合特征提取 | $100\%$ | $7/3$ | 模型对数据集的数据分布较鲁棒 |
| Gradient Boosting 混合特征提取 | $100\%$ | $7/3$ | |
| Conv1d Neural Net | $99.1\%$ | 使用数据增强技巧划分数据集 | |
| KNN混合特征提取 | $100\%$ | $7/3$ | |
| MLP 混合特征提取 | $100\%$ | $7/3$ | |
| SVM 时频域特征提取 | $100\%$ | $7/3$ |
项目进度
gantt
title 无法识别小组项目进度
dateFormat YYYY-MM-DD
section 平台调研
了解规则 : done, 2020-04-01, 6d
section 问题分析
分析规则 :done, 2020-04-02, 6d
分析数据 :done, 2020-04-07, 14d
section 问题背景调研
轴承检测问题调研 :done, 2020-04-09 , 9d
已有算法复现 :done, 2020-04-15, 9d
section 分类模型设计
编译环境配置 :done, 2020-04-09,8d
特征选择与提取:active, 2020-04-20,19d
分类器选择:active, 2020-04-28,15d
section 模型测试
不同模型结果获得 :2020-05-09,10d
不同模型结果测试 :2020-05-14,10d
References
- Voice Classification with Neural Networks
- Build your own Speech-to-Text Model
- 语音识别传统方法
- Random Forest Algorithm with Scikit-Learn
- Introduction to 1D Convolutional Neural Networks in Keras for Time Sequences
- GRU & LSTM
- ML Classifiers Animation
-
Xiaoyuan Zhang, Jianzhong Zhou,Multi-fault diagnosis for rolling element bearings based on ensemble empirical mode decomposition and optimized support vector machines,Mechanical Systems and Signal Processing ↩︎
-
G.F. Bin, J.J. Gao, X.J. Li, B.S. Dhillon,Early fault diagnosis of rotating machinery based on wavelet packets—Empirical mode decomposition feature extraction and neural network,Mechanical Systems and Signal Processing. ↩︎
-
Qingbo He,Time–frequency manifold for nonlinear feature extraction in machinery fault diagnosis,Mechanical Systems and Signal Processing ↩︎