Novel Training Techniques
Self-Supervised Representation Learning
Reference: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
Self-supervised learning opens up a huge opportunity for better utilizing unlabelled data, while learning in a supervised learning manner. This post covers many interesting ideas of self-supervised learning tasks on images, videos, and control problems.
Pseudo-Labeling to deal with small datasets — What, Why & How?
Reference: https://towardsdatascience.com/pseudo-labeling-to-deal-with-small-datasets-what-why-how-fd6f903213af
To climb the AI ladder with supervised learning may require “teaching” the computer all the concepts that matter to us by showing tons of examples where these concepts occur. This is not how humans learn: yes, thanks to language we get some examples illustrating new named concepts that are given to us, but the bulk of what we observe does not come labeled, at least initially.
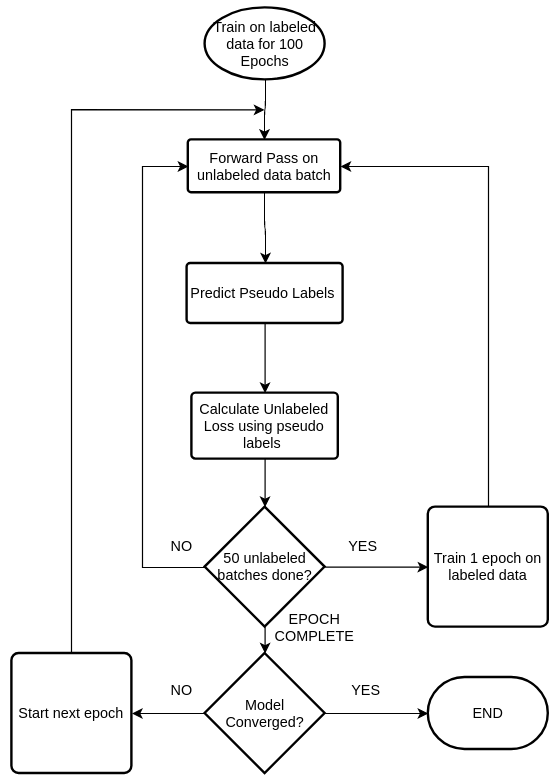
The Illustrated Self-Supervised Learning
Reference: https://amitness.com/2020/02/illustrated-self-supervised-learning/
To apply supervised learning, we need enough labeled data. To acquire that, human annotators manually label data(images/text) which is both a time consuming and expensive process. There are also fields such as the medical field where getting enough data is a challenge itself.
Understanding few-shot learning in machine learning
Reference: https://medium.com/quick-code/understanding-few-shot-learning-in-machine-learning-bede251a0f67
As the name implies, few-shot learning refers to the practice of feeding a learning model with a very small amount of training data, contrary to the normal practice of using a large amount of data. This technique is mostly utilized in the field of computer vision, where employing an object categorization model still gives appropriate results even without having several training samples.