Winner of the CVPR 2026 OpenSUN3D Challenge
Winner of the Open-Vocabulary 3D Affordance Grounding track at the CVPR 2026 OpenSUN3D Challenge.
I’m a PhD student in Computer Science at  , working with
Prof. Alexander Mathis in the
Mathis Group for Computational Neuroscience and AI. My research focuses on multimodal and continual learning for embodied systems, connecting perception, reasoning, and motor control.
, working with
Prof. Alexander Mathis in the
Mathis Group for Computational Neuroscience and AI. My research focuses on multimodal and continual learning for embodied systems, connecting perception, reasoning, and motor control.
Before my PhD, I completed an MSc in Robotics at EPFL and a master’s thesis at ![]() on continual skill learning for ANYmal, supervised by
Prof. Marco Hutter and
Prof. Caglar Gulcehre. I was also a student researcher at
on continual skill learning for ANYmal, supervised by
Prof. Marco Hutter and
Prof. Caglar Gulcehre. I was also a student researcher at  Zurich, where I worked on
InkSight, an open-source system for converting images of handwriting into digital ink.
Zurich, where I worked on
InkSight, an open-source system for converting images of handwriting into digital ink.
Earlier, I worked at EPFL CVLab on efficient 6D object pose estimation with modular quantization-aware training, at ![]() ByteDance AI Lab on multimodal representation learning, and on projects in 3D perception and Cryo-ET generative modeling.
ByteDance AI Lab on multimodal representation learning, and on projects in 3D perception and Cryo-ET generative modeling.
Outside of research, I enjoy board games 🎲, soccer ⚽, tennis 🎾, and music 🎶. Feel free to reach out to me if you want to join in on a hike or play some board games.
I’m open to collaborations with doctoral students and motivated Master’s students interested in continual learning, multimodal systems, embodied AI, and computational neuroscience.
If you have a solid deep learning foundation and want to work on these topics, I’d love to chat about potential research projects. EPFL Master’s students should also follow the instructions on our lab website.

Student Researcher, 2023 - 2024
Google Research
Computer Vision Research Intern, 2021
ByteDance AI Lab
Visit my scholar page for full list
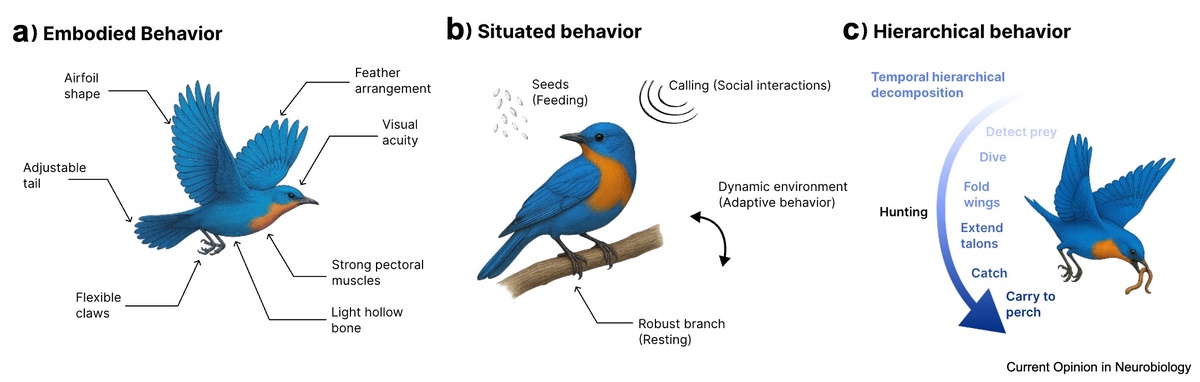
A perspective on behavior as embodied, situated, and hierarchical, and on how physics engines, computer vision, and multimodal language models can support richer quantitative analysis of animal behavior.

An open-source framework for scalable motion imitation learning with physiologically realistic, muscle-actuated humanoids — two validated musculoskeletal embodiments (126- and 416-muscle) plus GPU-parallel training of generalist motor policies.
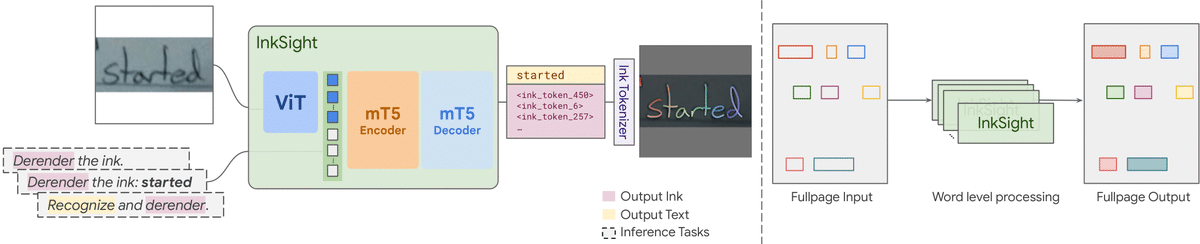
Our work aims to bridge the gap between images of handwriting and digital ink with a Vision Language Model (PaLI). To our knowledge, this is the first work that effectively does so with arbitrary photos with diverse visual characteristics and backgrounds. Furthermore, it generalizes beyond its training domain and can work on simple sketches. Human evaluation reveals that 87% of the samples produced by our model on the challenging HierText dataset are considered valid tracings of the input image, and 67% look like pen trajectories traced by a human.

Thesis Title: Continuous Skill Learning For ANYmal Robot
Supervisors: Chenhao Li, Nikita Rudin, Skander Moalla, Marco Hutter, Caglar Gulcehre (hosting supervisors from CLAIRE, EPFL)
Worked on extending Vision-Language Model with ink modality.
Supervisors: Andrii Maksai, Claudiu Musat, Jesse Berent, Henry Rowley.
Worked on modular quantization-aware training.
Supervisors: Saqib Javed, Mathieu Salzmann
